When utilizing the Upsert Destination, you might come across the following error:
Cause
The error indicates a data conversion problem in an SSIS (SQL Server Integration Services) pipeline.
The source column, of type String, cannot be converted to the specified target column of type nvarchar, leading to a potential truncation issue.
An error is being generated by MS SQL Server (System.Exception) while attempting to load source data using the Upsert Destination. Unfortunately, we have limited control over system-generated errors, which is why we cannot determine the exact column name that causing this error.
To address this issue
- Confirm matching data types between source and target columns.
- Check and adjust column lengths to avoid data truncation.
- Review and correct column mappings in the SSIS package.
- Examine the specific data causing the error in the mentioned row (RowNumber=x).
Let’s consider an example
When attempting to load a larger length of string data into a target table with a shorter length column. The error occurs due to data truncation in this scenario. We have a column in my MS SQL table with a data type of nvarchar(100).
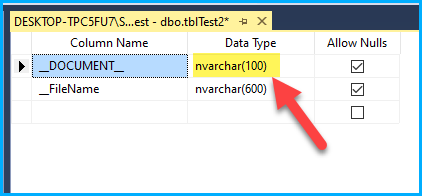
When attempting to load data from a source column with a DT_Ntext type into the target column with a length of nvarchar(100), We encounter the same error.
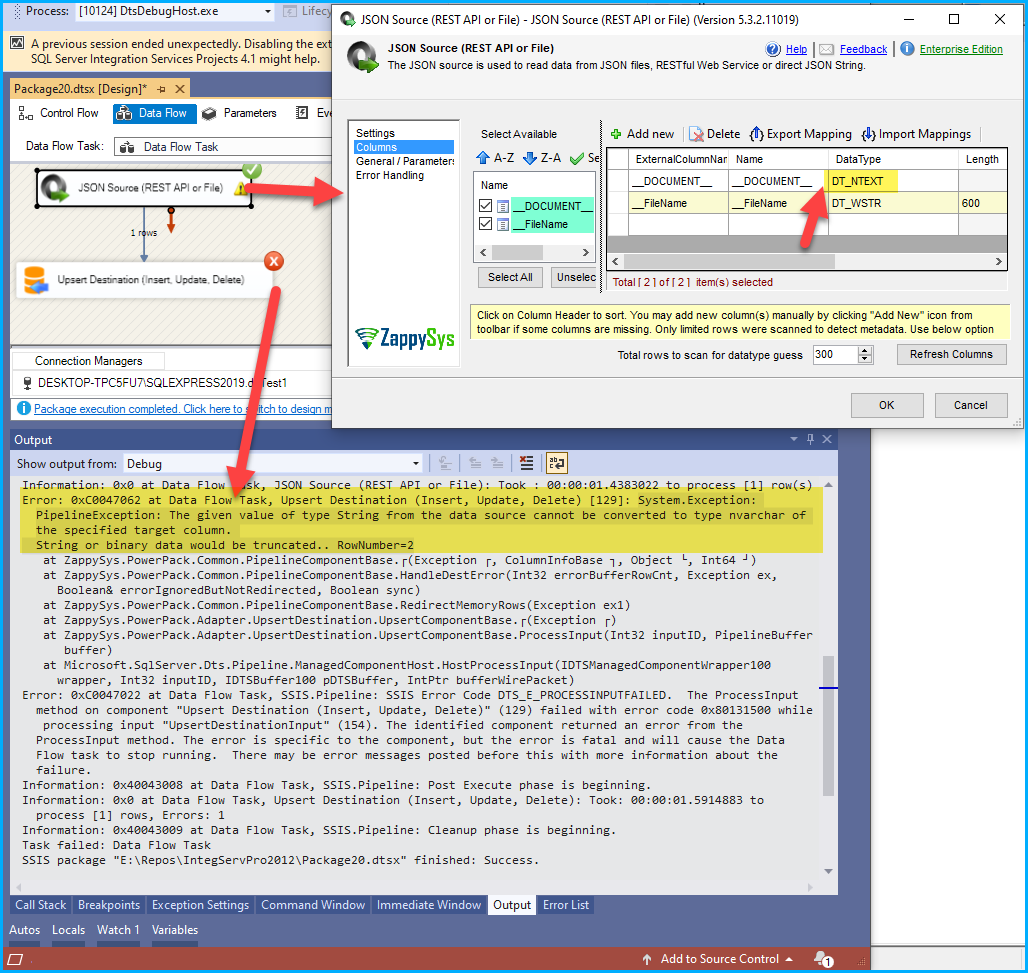
To address this issue, it’s necessary to align the data types of the target SQL table columns with the source columns (NText, in this instance), to resolve the error.
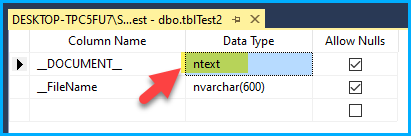
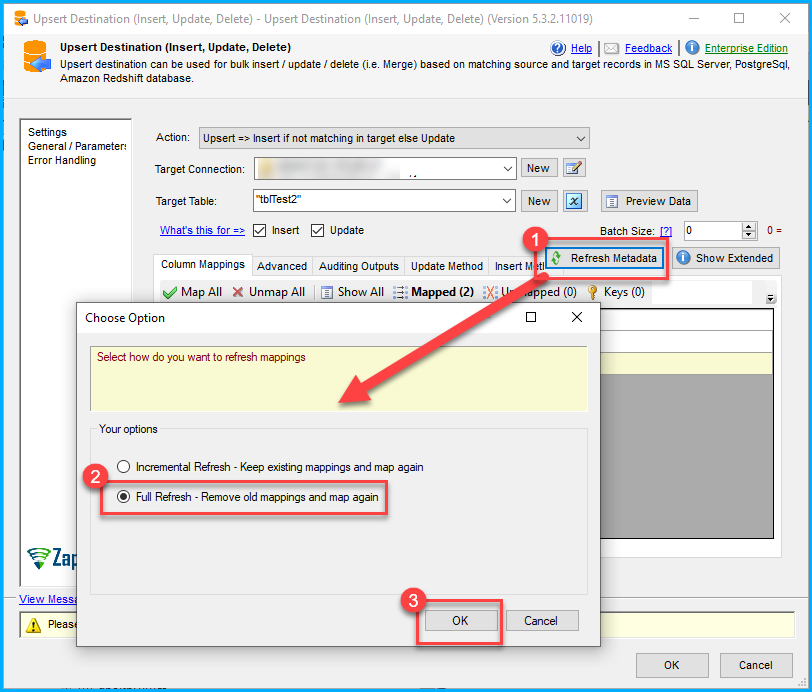
After modifying the data type in the SQL table, it’s crucial to refresh the metadata columns in the Upsert Destination also, to reflect the changes made to the target table.
- Open the Upser Destination
- Click on the Refresh MetaData button
- Select the Full Refresh Option and click on OK.
- Map the Key Column(s) and close the Upsert Destination by clicking OK.
That’s it. Run the package, and if all the column mappings are correct, it should be successful.

Short Answer
Change the data type from nvarchar(size) to nvarchar(Max) or ntext in the Target SQL Table, as it is an issue of string length size.
If your data contains Unicode characters and exceeds 4000 characters, consider using the ‘DT_NTEXT’ data type to ensure proper handling of the extended character set. This datatype is suitable for scenarios where Unicode characters require storage beyond the 4000-character limit.
If the data primarily consists of ASCII characters and exceeds 4000 characters, it is advisable to use the ‘DT_STR(8000)’ data type. On the other hand, if the ASCII character count surpasses 8000, consider using ‘DT_TEXT’ for proper storage and handling of longer character strings.