Introduction
Duplicate rows can occur frequently in JSON API or files, especially when aggregating data from various sources. Removing these duplicates efficiently is crucial for maintaining clean data and accurate insights.
This article will show you how to remove duplicate rows from a JSON source using the ZappySys SSIS PowerPack and create a new JSON file with JSON destination. This will ensure your data remains clean, organized, and ready for further processing or analysis.
Prerequisites
- SSIS PowerPack: Download and install the ZappySys SSIS PowerPack from the Customer Download Area or the trial version.
Steps
-
Add a Data Flow Task to your SSIS package.
Inside the Data Flow, drag and drop a JSON Source. Enter a valid URL or JSON file path. For this example, we will use the following JSON data with duplicate entries in the employee records:{ "store": { "employees": [ { "name": "bob", "age": 21, "location": "B1", "hiredate": "2020-01-01" }, { "name": "ken", "age": 25, "location": "C1", "hiredate": "2020-01-03" }, { "name": "bob", "age": 21, "location": "B2", "hiredate": "2015-01-01" }, { "name": "sam", "age": 30, "location": "A1", "hiredate": "2015-01-02" }, { "name": "bob", "age": 21, "location": "B3", "hiredate": "2015-01-01" }, { "name": "sam", "age": 30, "location": "A1", "hiredate": "2015-01-02" }, { "name": "ken", "age": 25, "location": "C1", "hiredate": "2015-01-03" }, { "name": "bob", "age": 21, "location": "B1", "hiredate": "2015-01-01" } ], "location": { "street": "123 Main St.", "city": "Newyork", "state": "GA" } } } -
Preview the data in the JSON Source, filter to extract the
employeesobject, and save the configuration. -
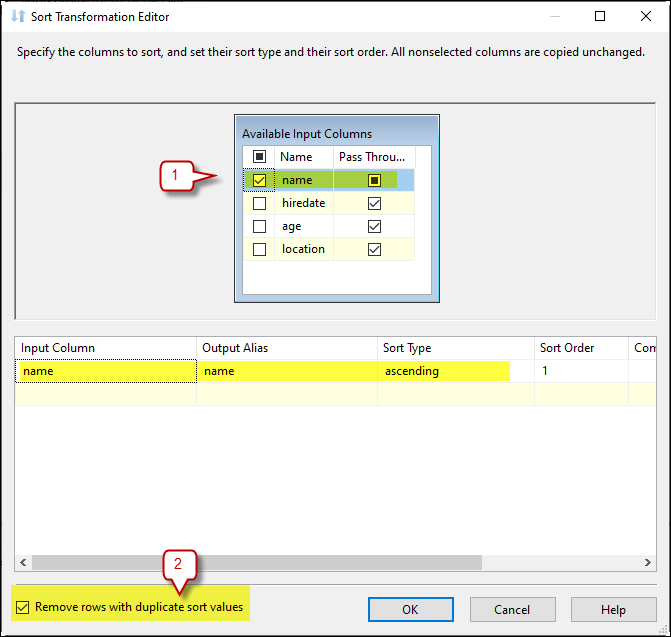
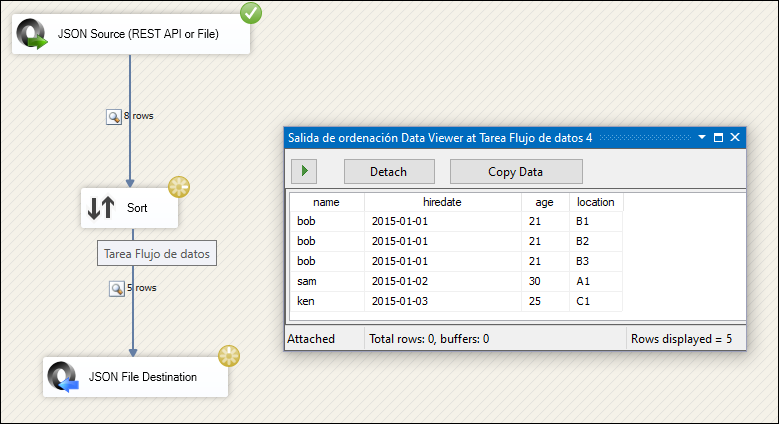
Drag a Sort Transformation component and connect it to the JSON Source. In the Sort Transformation editor, select the column (or columns) where duplicates exist. Check the box Remove rows with duplicate sort values and save the configuration.
-
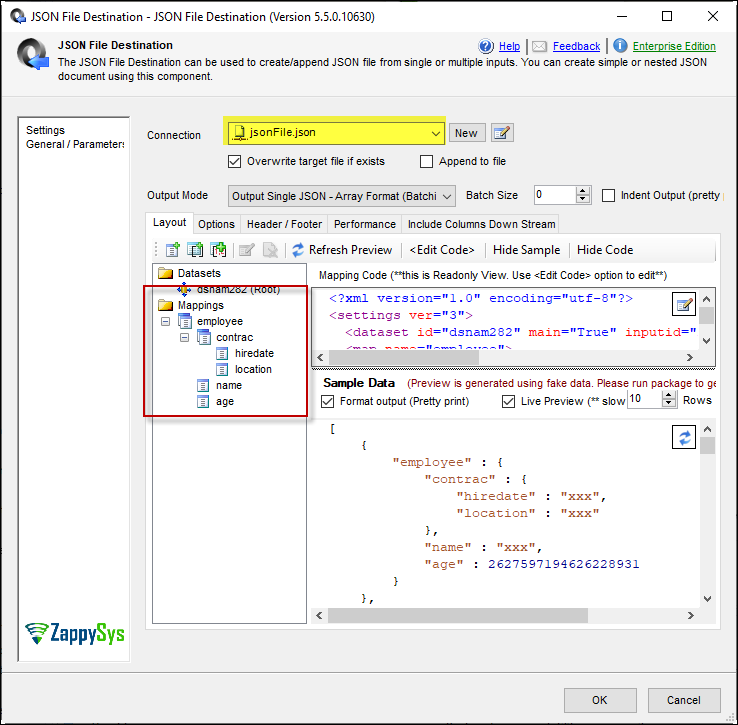
Drag a JSON Destination component and connect it to the Sort Transformation. Configure it to create a new JSON file that stores the deduplicated data and saves the configuration.
-
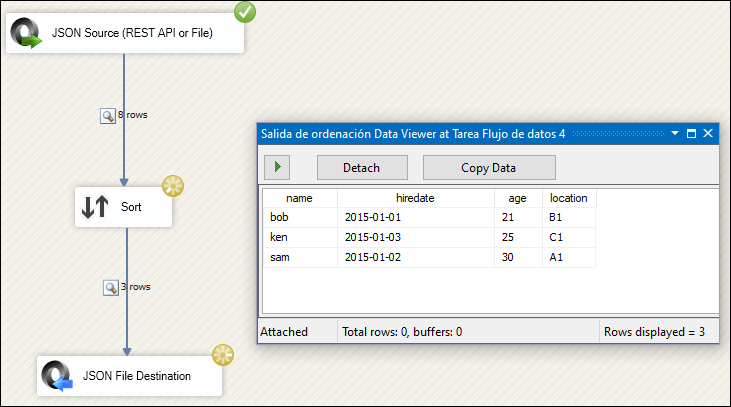
Execute the package. The resulting output will show fewer rows. By removing duplicates, the JSON data will now contain unique entries. In our example, the eight original rows are reduced to three unique rows.
-
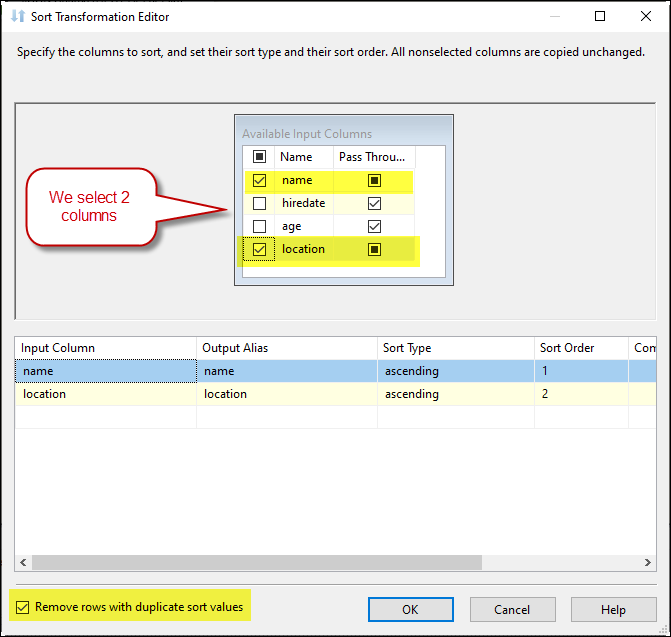
If necessary, define duplicates using more than one column in the Sort Transformation. Select two or more columns for advanced deduplication.
-
Rerun the package for different results based on your column selections after modifying the columns.
Video Tutorial

Conclusion
Following these steps, you can easily remove duplicate rows from your JSON source and create a clean, organized JSON file with ZappySys SSIS PowerPack. This streamlined process simplifies data integration and enhances the accuracy of your data reporting. Should you face any issues or need further assistance, our support team is ready to help via chat on our website or email at support@zappysys.com.
References
For more details on working with JSON files in SSIS, visit our JSON Source and JSON Destination documentation.